【工业与大数据】大数据的主要处理框架与工具

大数据作为一门应用广泛的技术,在不同的应用场景下对其数据结构,处理实时性都有不同的需求,所以大数据技术的先驱们开发了许多不同的技术框架来满足不同的需求。本章主要介绍大数据所采用的的主流处理框架以及其技术细节。
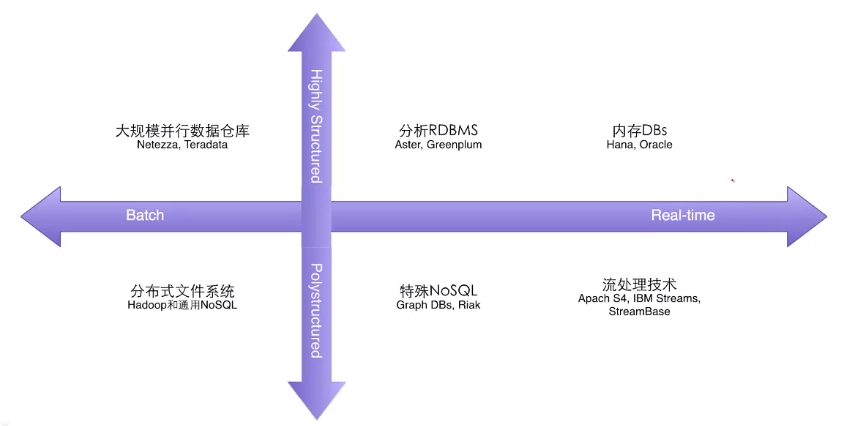
- 大数据处理工具分类
一、几个重要的概念
大数据技术的几个重要的观点,这个也是贯穿在整个大数据技术的重要思想
- 分布式:数据存储于成百上千个服务器中
- 大数据块:大数据块减少元数据的开销
- 失败无法避免:使用商用硬件 → 失败是不可避免的,所以买便宜的硬件
- 简洁的才是稳定的:简洁的一致性模型(单写者,避免相互等待)
数据并行化(DLP)
- 若干硬盘上的大量数据,可以被并行化的操作(比如,操作文档) Embarrassingly Parallel
这是什么意思呢?将数据分隔成不同的,相互无关的数据块就能实现数据并行化。我们举个例子:
词频统计 从多个数据中找到dog的发生次数,我们只需要把数据分成不同的块,同时进行查找,没找到一个dog,就返回一次结果。这样就能显著提高查找效率,这也是一种很朴实的观点。
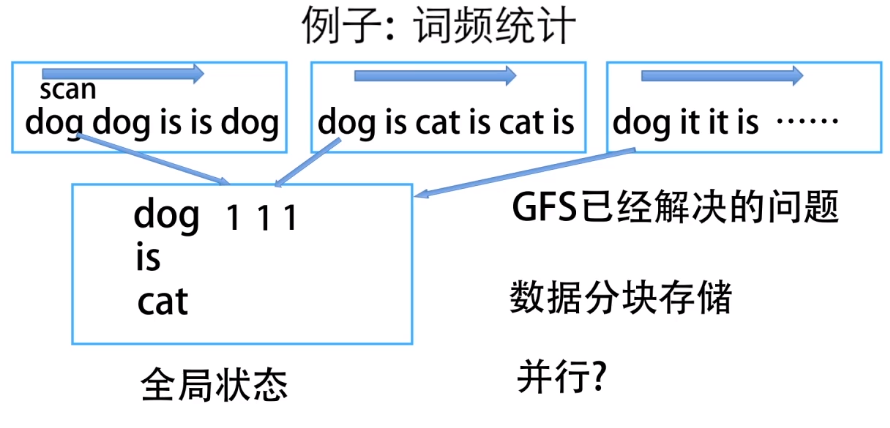
但是这样的解决方案也衍生了两个问题:
- 共享的状态
- 吞吐量(多个进程同时改变)
- 同步(同时修改需要锁)
- 小粒度的通信让元数据管理变得复杂
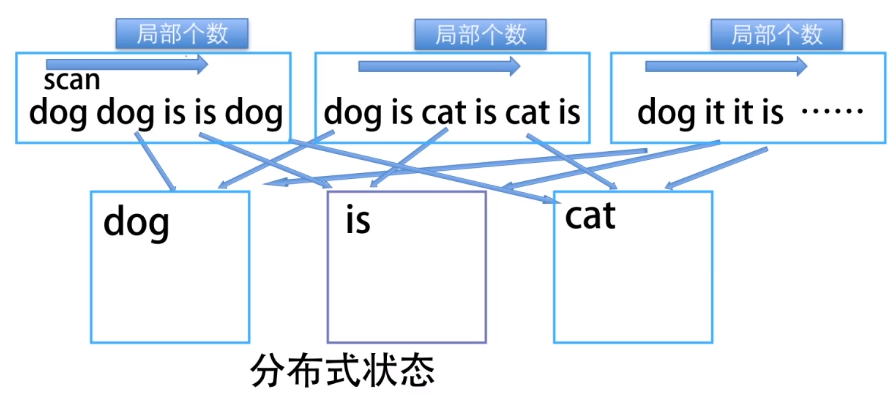
为了解决这样的问题,我们将每个数据块看做一个单元,每个单元全部数完后将结果一次性返回。
看似很美好,但是又又又衍生出两个问题:
- 失败的机器(某个机器发生错误无法及时发现异常)
- 共享的状态太大(返回的数据量太大)
所以我们将全局状态也作为分布式状态,并且将每个数据块的存储状态保存下来。这样就满足了分布式处理的需求。
以上提到的设计理念,就是MapReduce的设计理念。接下来我将对MapReduce进行详细介绍。
二、MapReduce
MapReduce Process —— 数据并行的分治策略
-
Map
- 将数据分割为shards或者splites,将它们分配给工作节点,将工作节点来计算子问题的解。
-
Reduce
- 收集,合并子问题的解
-
易于使用
- 开发者可以集中解决数据处理的问题
- MapReduce系统负责解决其他细节
MapReduce是很早就提出的想法,是算法设计中常用的策略。但是其技术特点非常符合大数据的技术需求,很好的解决了大数据系统的需求,让开发者集中精力进行数据处理,而不用考虑数据内部的细节。
MapReduce 的基本编程模型
-
Map
- map(in_key,in_value) → list(out_key,intermediate value)
- 处理输入的键值对
- 生成中间结果集
- map(in_key,in_value) → list(out_key,intermediate value)
-
Reduce
- reduce(out_key,list(intermediate_value)) → list(out_value)
- 对于某个键,合并他所有的值
- 生成合并后的结果值集合
- reduce(out_key,list(intermediate_value)) → list(out_value)
例子: 词频统计
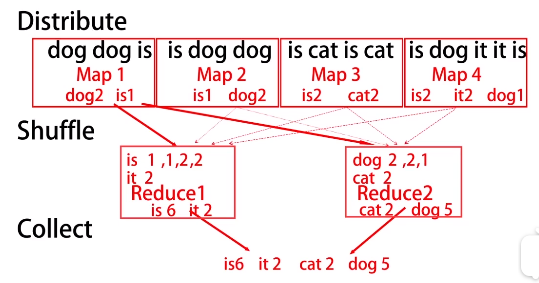
MapReduce算法的程序实现是非常简洁的
map(String input_key,String input_value):
//input_key:document name
//input_value:document contents
local Count = CountLocally(input_value);
foreach count:
Emit(word,count); //Produce count of words
reduce(String word,Iterator intermediate_values):
//word:the word(in the intermediate key);
//intermediate_value:a list of counts;
int result = 0;
for each v in intermediate_values;
result += v;
Emit(word,result);

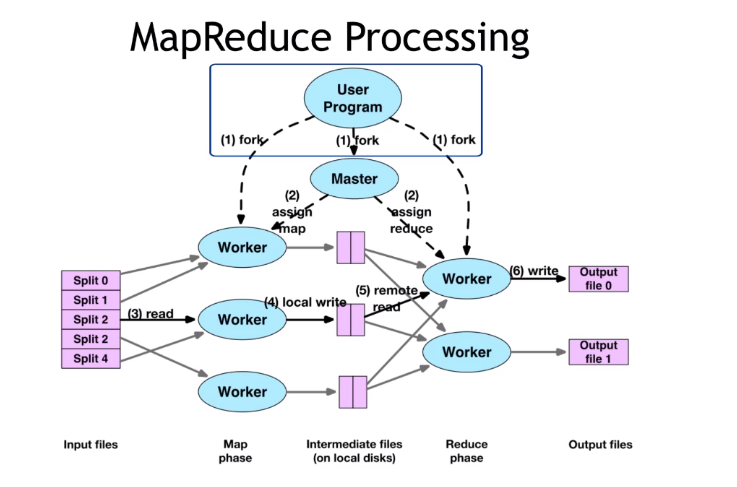
MapReduce 的执行步骤
- 将输入数据分隔成M块,在每块上分布式的调用map()
- 通常每个数据魁岸16MB或者64MB
- 取决于GFS的数据库大小
- 输入数据由不同的服务器并行处理
- 通过将中间结果分割成R块,对每块分布式的调用Reduce()
- M和R的数量由用户指定
- M>>#servers,R>#servers
- 很大的M值有助于负载均衡,以及快速恢复
- 每个Reduce()调用,对应一个单独的输出文件,若依R值不应该太大
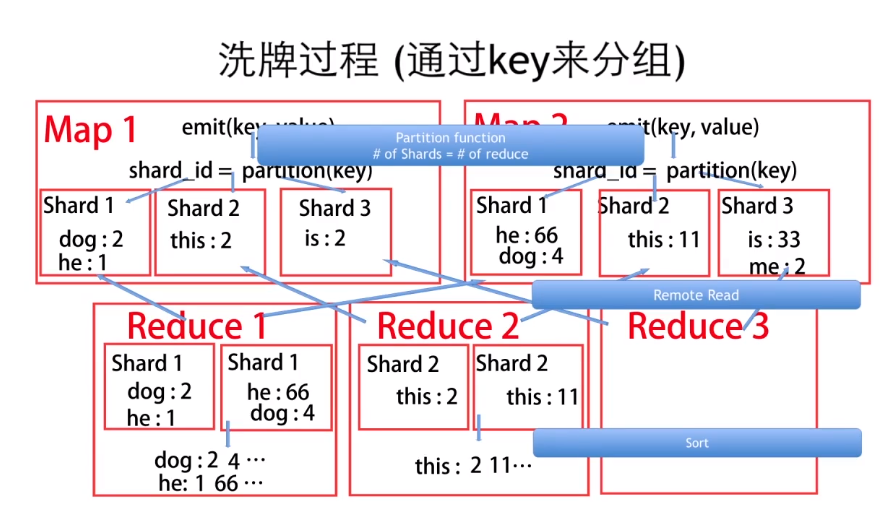
Map Recude的性能优化
- MapReduce 冗余执行
- 整个任务完成时间是由最慢的节点决定的
- 解决方案:在接近结束时,生成冗余任务 → 用其他机器同样进行冗余任务
- 谁最先完成,谁获胜
- 也叫做"投机"(speculative)执行
- 影响:极大的缩短任务完成时间
- 资源消耗增加 3%,大型任务速度提高 30%
MapReduce所有的操作都是独立且幂等的,所以不存在同步性问题
- MapReduce故障处理
- 计算节点故障
- 控制节点通过周期性的心跳来检测故障
- 重新执行
- 主节点故障
- 可以解决,但是目前还没有解决(控制节点故障可能性很低,所以就直接重启即可)
- 健壮性
- MapReduce论文报告:曾经丢失1800个节点中的1600个,但是任务仍然正确完成.
- 计算节点故障
Hadoop :MapReduce的开源实现
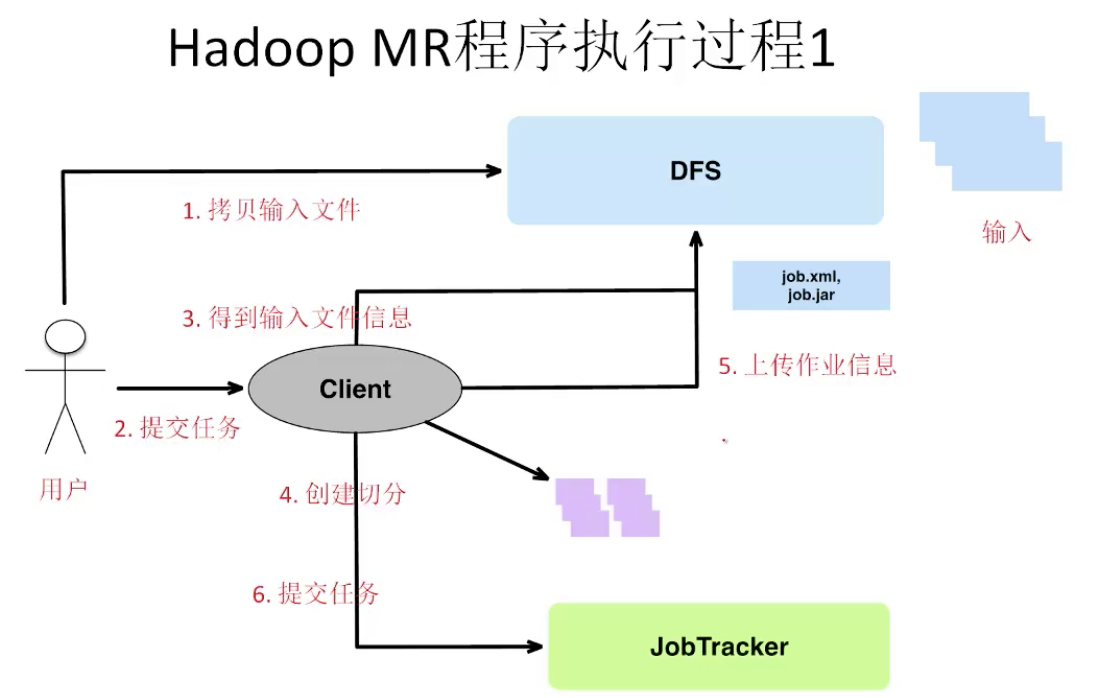
Hadoop MapReduce的基本架构
Hadoop不仅仅实现了文件分布式存储和MapReduce,还实现了一系列容错、资源远离等服务
- JobTracker(Master)
- 接收MR作业
- 分配任务给Worker
- 监控任务
- 处理错误
- TaskTracker(worker)
- 运行Map和Reduce任务
- 管理中间输出
- Client
- 提交作业的界面
- 得到多样的状态信息
- Task
- 一个独立的过程
- 运行Map/Reduce函数
Hadoop MR程序执行过程 1
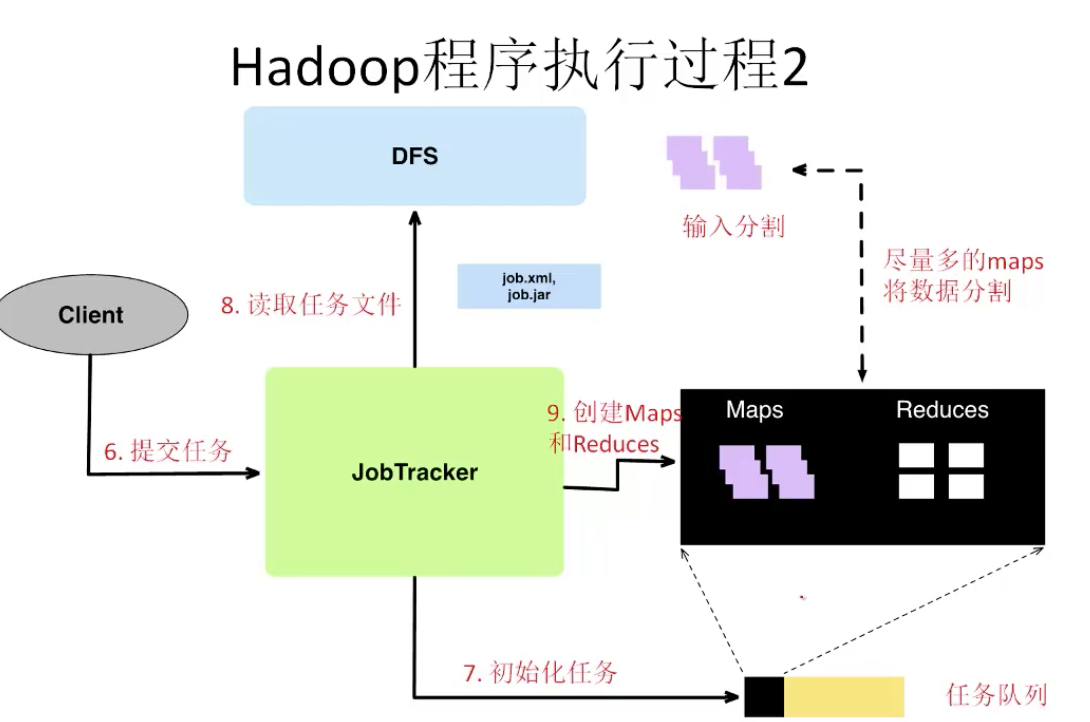
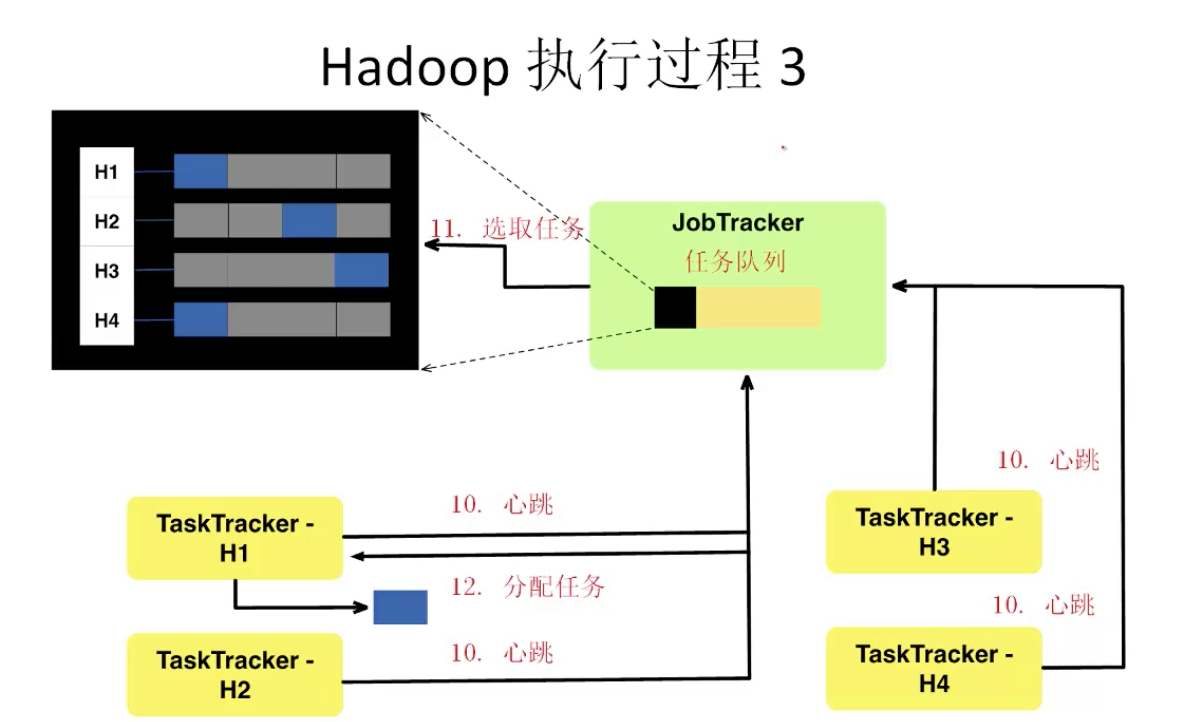
MapReduce总结
MapReduce的理解要点
- 同样的细粒度操作(Map&Reduce)重复作用于大数据
- 操作必须是确定性的
- 操作必须是幂等的,才没有副作用
- 只有shuffle过程中才有通信
- 操作(Map&Reduce)的输出存储于硬盘上
MapReduce的作用
- Google
- 为Google Search建立索引
- 为Google News进行文章聚类
- 统计行的机器翻译
- Yahoo!
- 为Yahoo!Search建立索引
- 为Yahoo!Mail进行垃圾检测
- Facebook
- 数据挖掘
- 广告优化
- 垃圾检测
MapReduce优点
- 分布式过程完全有名
- 没有一行分布式编程(方便,有保证正确性)
- 自动的容错性
- 操作的确定性保证了故障的任务可以在其他地方再次运行
- 保存的中间结果保证了只需要重新运行故障reduce节点
- 自动的规模缩放
- 由于操作是没有f副作用的,所以他可以动态的被分发到任何数量的机器
- 自动的负载均衡
- 及时移动任务,投机性的执行慢的任务
MapReduce缺点
- 及其严格的数据流
- 很多常见的操作也必须手写代码
- 程序语义隐藏在map-reduce函数中:自动的维护,扩展,优化都比较困难
三、PIG LATIN 编程语言
PIG LATIN本意是英语中一种“黑话”的规则,其规则就是将单词首字母放置在最后并加上ey,比如“happy” ➡️ “appy-hey”
在大数据技术中,PIG LATIN是一种高于MapReduce的可以处理任意数据流的大数据处理系统(也是一种语言)。
为了说明PIG LATIN的作用,我们可以举个例子
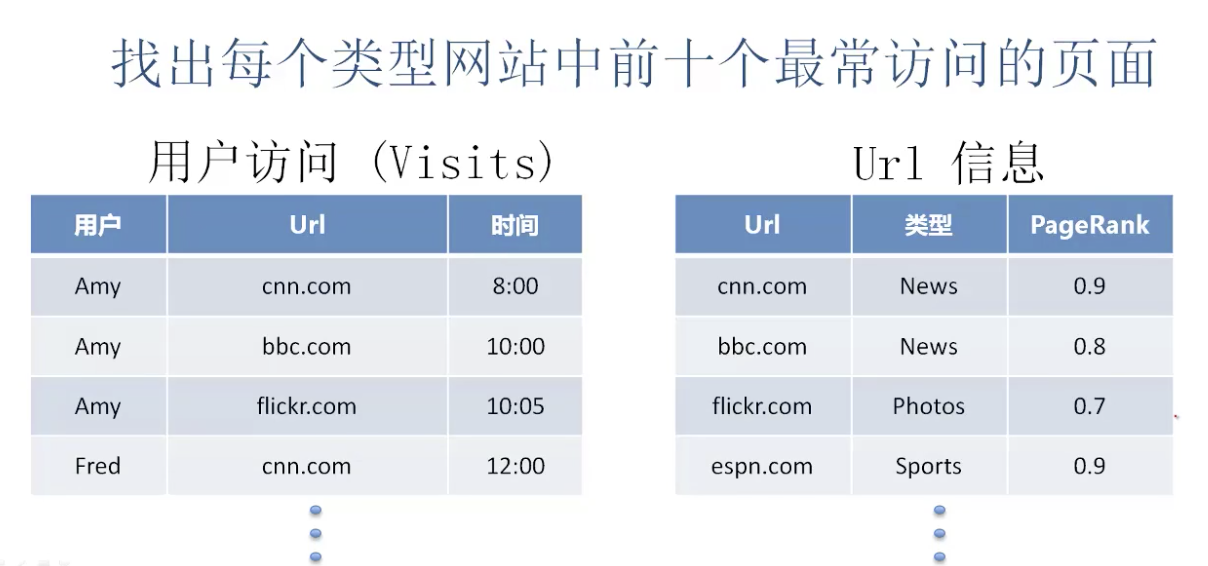
为了解决这个需求,传统的SQL 需要将两个表 Join在一起,再通过Group by,count的方式进行查询。但是显而易见,在互联网中这两个表可能是非常非常非常大的,他们只能被分布式的存储在不同的机器中,那么如何进行查询和运算呢?
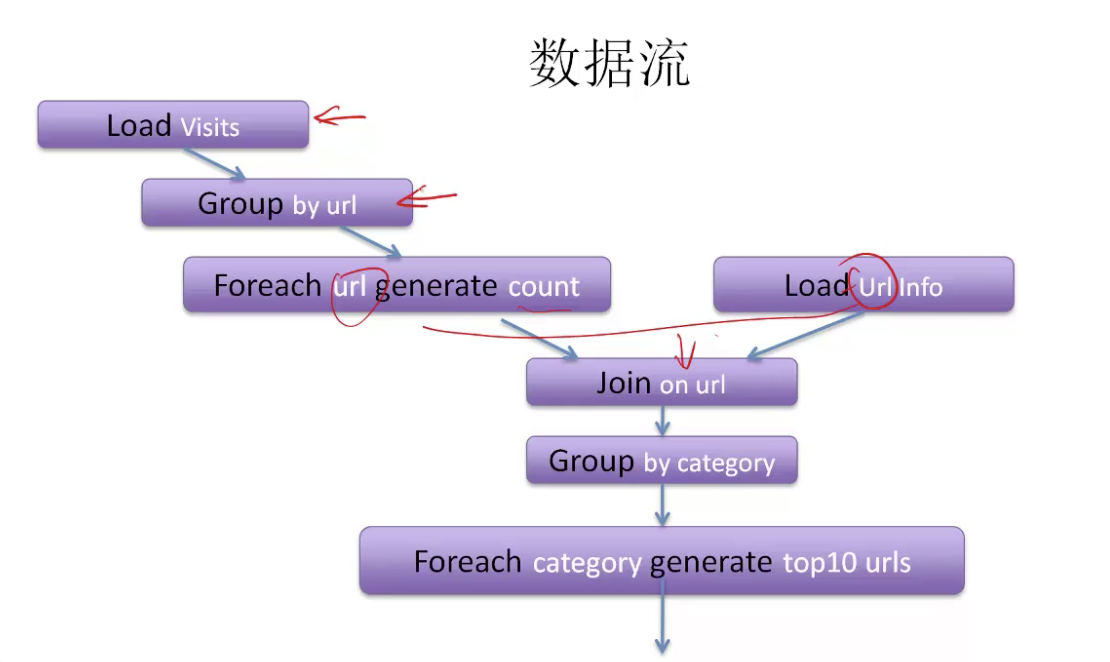
如果通过MapReduce进行运算,则需要将不同的MapReduce结合起来多次运算,最主要的MapReduce需要参数具有相同的数据类型,我们可能还涉及到数据类型的转换,这样就产生了大量的代码,也很难进行维护

因此,Yahoo!发明了PIG LATIN语言。
- 更高级的编程语言
- 更快捷的MapReduce工作流程
- 提供关系型数据库操作(例如JOIN,GROUP BY)
- 可以方便地潜入JAVA函数
- 最先在Yahoo!Research使用
- 当是运行Yahoo!大约50%的任务
3.1 PIG LATIN的基本语法
visits = load '/data/visits' as (user,url,time);
gVisits = group visits by url;
vistCounts = foreach gVisits generate url,count(visits);
urlInfo = load '.data.urlInfo' as (rul,categroy,pRank);
visitCount = join visitCounts by url,urlInfo by url ;
gCategories = group visitCounts by category;
topUrls = foreach gCategories generate top(vistCounts,10);
sotre topUrls into 'data/topUrls';
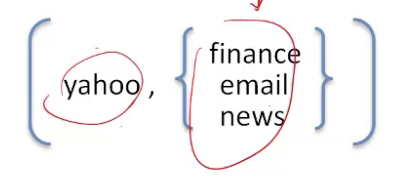
嵌套的数据结构
- Pig Latin采用完全可以嵌套的数据结构
- 原子值(Atomic Values),元组(tuples),包(列表,bages(lists)),映射(maps)
-
优势
- 对于开发者,比数据库的扁平组(flat tuple)更自然
- 避免代价昂贵joins操作
-
嵌套数据模型
- 解耦grouping操作作为一个独立的操作
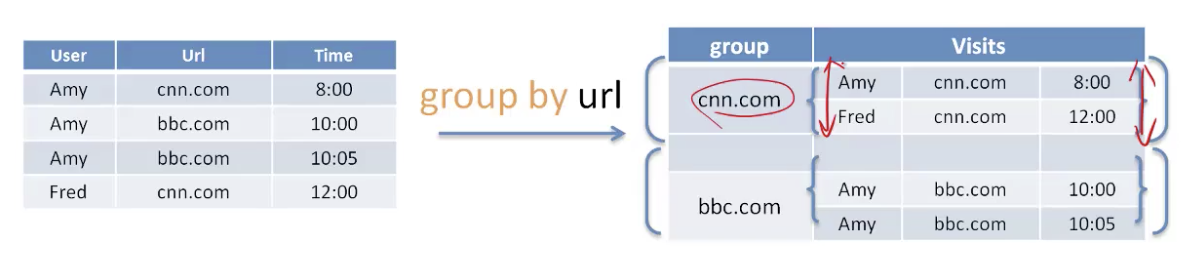
- 共同分组(CoGroup) 性能优化
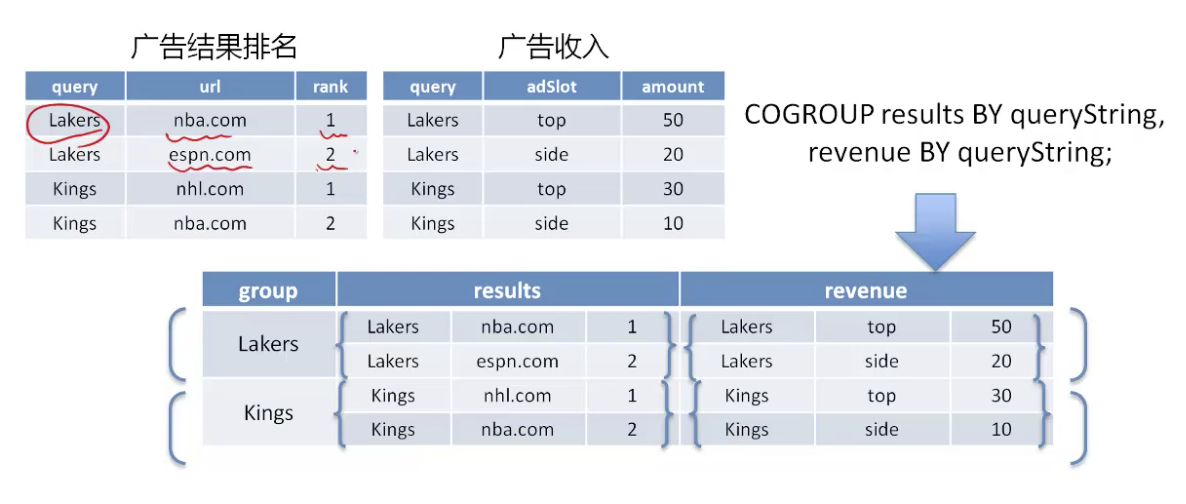
- 解耦grouping操作作为一个独立的操作
3.2 Pig Latin的实现与优化
User ➡️ PIG(或者写SQL)➡️Hadoop Map-Reduce ➡️cluster
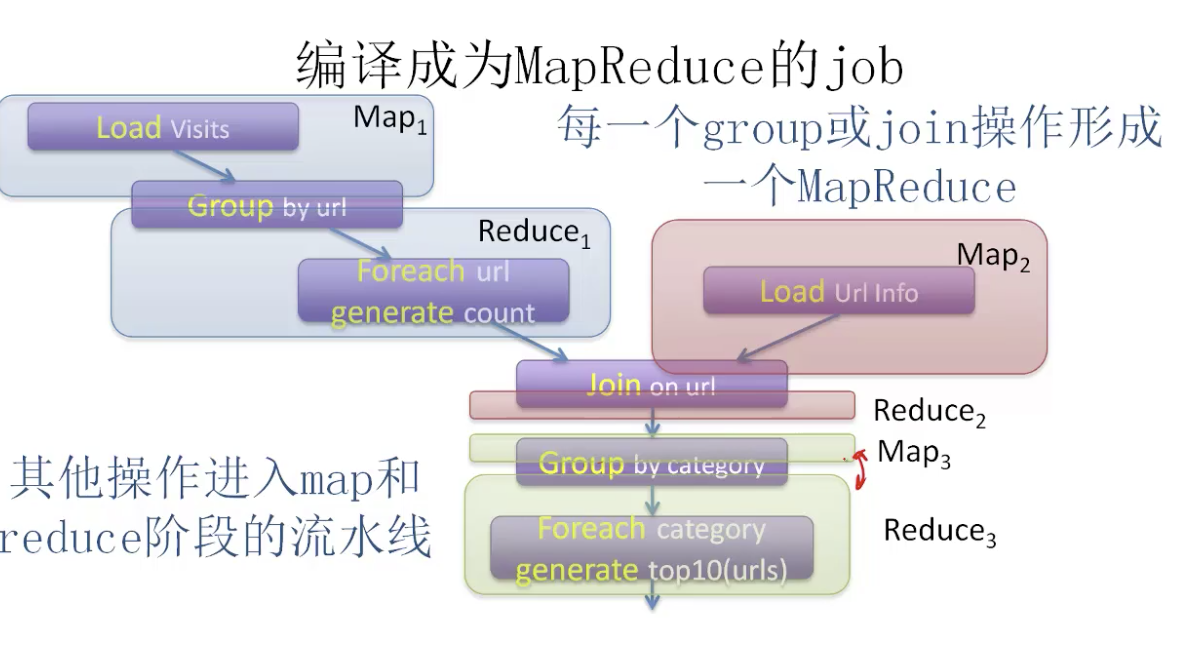
Pig Latin 翻译为 Map-reduce的方法
- 每一个group或join操作形成一个MapReduce
- 其他操作进入map和reduce阶段的流水线
-
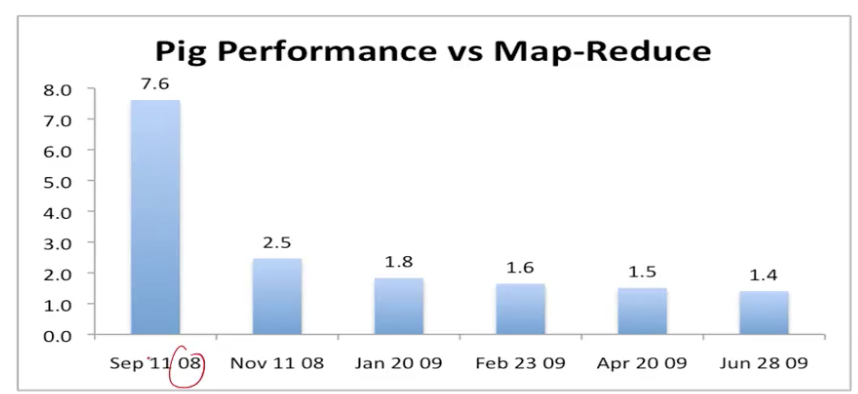
抽象的优势
- 抽象的程序更简单,计算机可以进行优化
- 可以逐渐优化,不影响用户使用
-
Pig Latin的优化
- 合并函数(combiner)
- 中间过程传递数据越少越好,聚合求和运算越早执行越好
- 聚合函数
- 去掉重复数据(distinct)
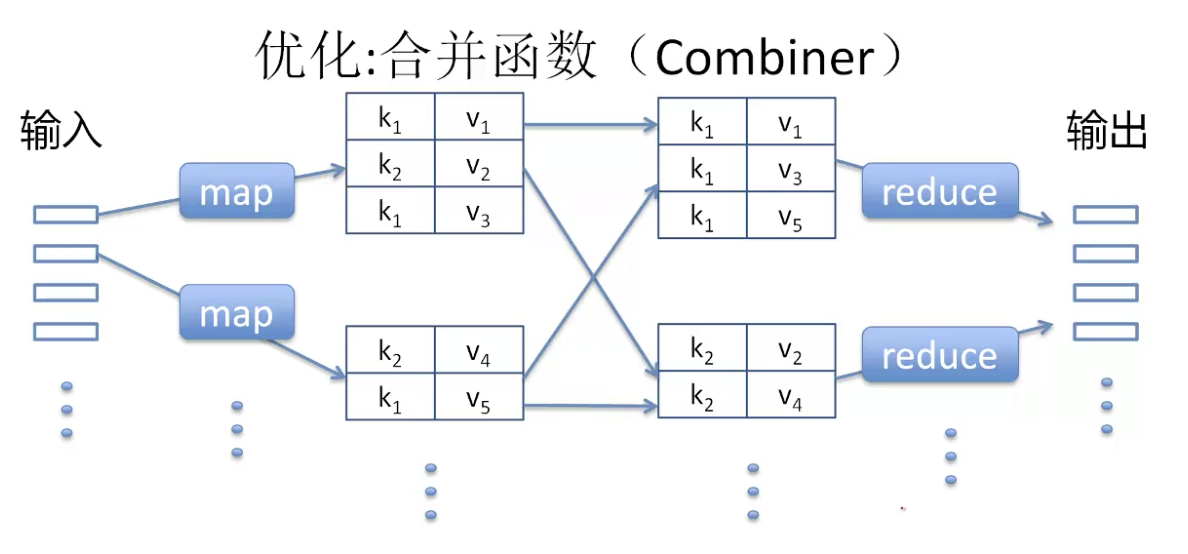
- 偏斜数据的链接(Skew Join)
- 如果很多值都有同样的健,就会有问题
- Skew join对数据进行采样,来找到高频值
- 在reducer中进一步分割这些数据
- 转化为map-oinly的任务
- 将很小的数据集作为旁路输入(“sid file”)
- 多数据流:PIG通过split将Map分为多个数据流,减少Reduce操作
- 合并函数(combiner)
四、其他类似框架
- Sawzall
- 基于MapReduce的数据处理语言
- 严格的结构:过滤➡️聚合
- Hive
- 基于MapReduce的类似SQL的语言
- DryadLINQ
- 基于Dryad的类似SQL的语言
五、总结
-
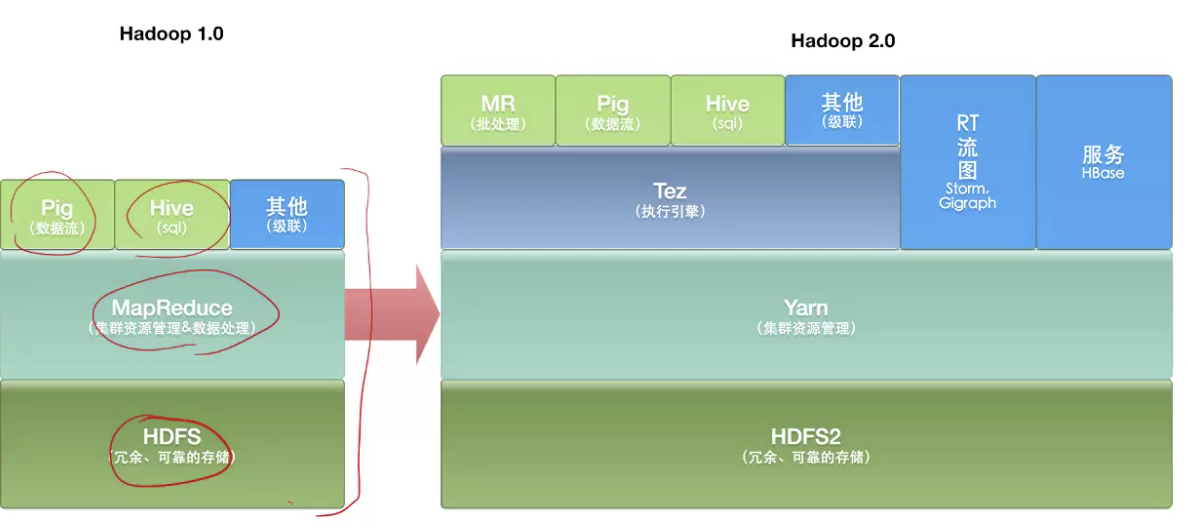
Hadoop与PIG
-
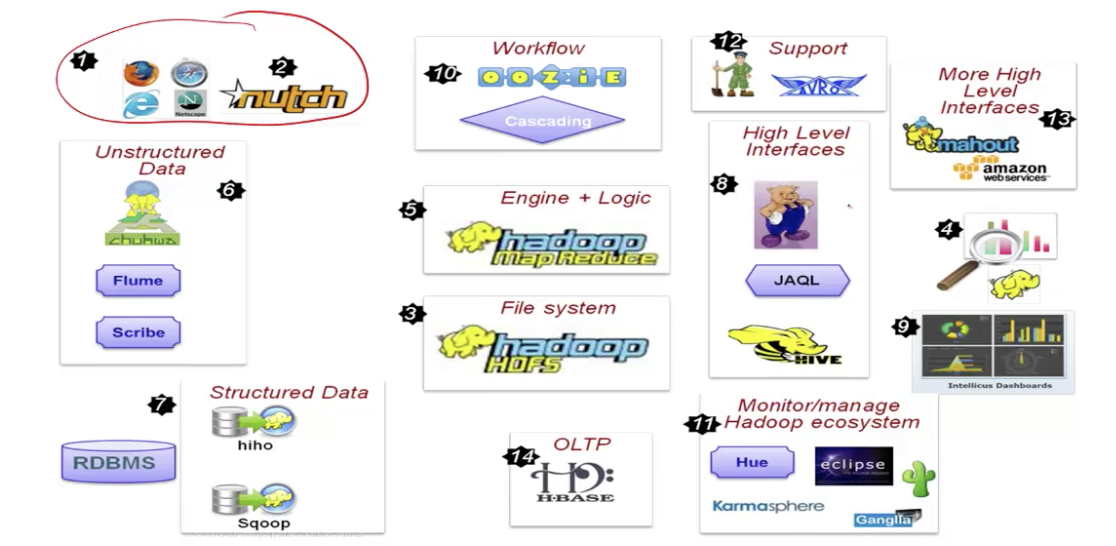
Hadoop 生态系统
-
另一面:“MapReduce: A major step backwards”
- David J.DeWitt,Michael Stonebraker
- 在编程模式中后退了一大步
- 没有模式,没有高级的访问语言
- 一个次优化的实现
- 它使用了暴力法搜索,而不是用任何索引
- 一点也不创新
- 25年前就有类似的技术
- 缺少了目前数据库管理系统一般都有的大多数特点
- 索引,更新,食物,完整性约束,逻辑视图