【工业与大数据】GFS:Google文件系统

为什么传统的NFS/AFS并不能满足大数据的需要?为什么GFS大名鼎鼎?它解决了什么样的问题?
一、Google文件系统
-
为什么需要一个不同的分布式文件系统?
- 为了建立搜索引擎,需要存储互联网容量的数据,支持数据快速写入到分布式文件系统中
- 为了支持查询,需要对大量数据进行处理,需要建立倒排索引,需要对网页数据进行排序
- 所有的技术革新,都是业务驱动的,业务需求决定了Google 文件系统的开发
-
GFS中的具体需求
- 需要一个分布式文件系统能够存储大量的数据
- 这样的文件系统建立在大规模X86集群之上,这些节点是廉价的,并且系统的模块还会出错
- 现有的文件系统无法满足Google对于存储数据的需求
- 整个硬件中的许多模块会出现出错的情况,出错会同时发生
- 有大量的超大规模文件(多个网页合并成的大数据文件),文件大小会超过数百G
- 读写模式(优化考虑):
- 文件系统读写大量是写入一次,多次读取的特性
- 写入并发,并发读取
- 延迟和带宽的考虑(高延迟,高带宽)
- 需要一个分布式文件系统能够存储大量的数据
二、如何设计Google文件操作系统
- 几个目标
- 要做一个文件系统(目录树,文件读写),支持读写非常大的文件
- 充分利用资源(负载均衡,扩展性)
- 容错(不能因为少数的节点出错就停止工作)
- 系统简洁(复杂的系统在涉及到数千个节点的时候无法理解与控制)
为了实现以上目标,Google给出了文件系统设计的基本设计:
- 文件系统的基本设计
- 数据块:由于文件的规模十分庞大,文件将会被划分为多个大小为64MB的数据块进行存储,这个数据块的大小远远大于一般文件系统数据块的大小(64K)
- 性能设计:依据全局动态信息,自动调整数据在不同服务器中的存放,服务器存储利用率相似,负载动态调整
- 可靠性:为了保证数据的可靠性,数据通过副本的方式保存在多个节点中,一般保存在3个节点以上
- 系统设计简化:通过单个节点保存文件系统的元数据,这个节点被称为Master节点,主借点来协调整个系统的访问流程。
三、分布式文件系统的设计
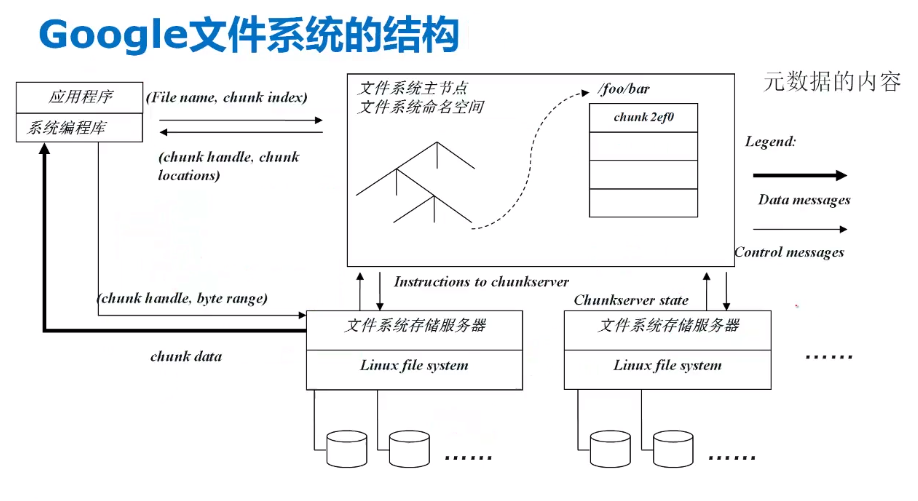
- 文件系统的主节点(存储元数据)
- 文件系统命名空间:将文件路径与chunk对应信息保存(chunkServer)
- 应用程序发送请求后,Master节点返回chunkhandle,chunklocations的信息,应用程序根据以上信息访问对应服务器。
四、GFS性能问题
根据之前的设计,我们很明容易就能发现这样的文件系统可能会存在两个问题:
- 所有的访问都会通过Master节点,可能会成为性能瓶颈
- master节点发生异常后整个文件系统都会出现异常
为解决以上问题:
- 主服务器的性能负载问题(主要的问题)
- 客户端数据缓存,每次请求获取1000chunk的元数据,减少客户端与元数据信息交互
- 元数据服务器存储在内存中
- 块服务器的负载均衡问题
- 不能让一部分块服务器出现性能瓶颈 (chunkServer)
- 负载必须要进行动态调整
- 块服务器的扩展性问题
在GFS中,一个64M的数据块大约需要64B元数据。10PB数据约需要 10GB的元数据控件(很容易可以满足)
五、GFS可靠性问题
- 块服务器的可靠性问题
- 快服务器出现错误怎么办? → master服务器发现块服务器不在线时,启动副本恢复
- 一个块服务器出现错误的时候,副本数目恢复所需要的时间 (不同的数据块从不同服务器并行恢复)
- 主服务器的可靠性问题
- 内存数据的可恢复性(日志操作,快速恢复,定期硬盘快照)
- 单个节点主服务器的可恢复性 → 影子(shadow)服务器
- 影子节点仍然会出现错误 → 硬盘快照保存多个副本
六、 GFS一致性要求
- 三副本一致性的基本要求
- 目标:维持每一个数据块的三个副本完全一样
- 方法:出事数据块都没有数据,出事数据相同,之后以相同的操作顺序执行客户端的操作
- 手段:基于租期以及主要副本的顺序定义
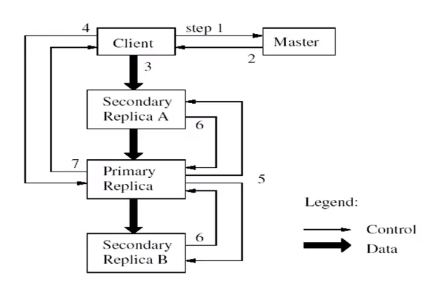
- GFS中写入操作对一致性的影响

- GFS 放松的一致性
- 一致的(Consistent):文件的三个副本一直
- 明确的(Defined):反映了客户端的操作
七、GFS的POSIX兼容性
GFS不是标准的文件系统,是建立在本地文件系统之上的应用层文件系统。GFS与标准的POSIX文件系统并不兼容,因此GFS上不能够运行程序,访问GFS需要一个客户端。
- 在数据的读写上,GFS的POSIX不一致主要表现在以下两个方面:
- 数据读写: GFS增加了Append操作,由文件系统确定写入地址,这是POSIX所没有的
- 数据一致性:POSIX不兼容,GFS定义了自己的数据一致性模型
兼容性哲学:通用的一般不是最优的策略
八、GFS的垃圾收集
- 垃圾收集
- 删除的数据不是直接从本地文件系统中删除,而是通过垃圾收集的方法,比传统的方法简单,并更加可靠
- 主服务器要日志记录删除操作,并将文件改名成隐藏的文件名
- 在系统负载不高的时候后台挥手隐藏的文件
- 过期副本的删除
- 整个系统在节点失效,并重新加入的时候产生过期副本数据
- 通过检查数据库的版本来探测到过期副本
总结
GFS实际上是演示了如何在现代市场上可见的硬件水平上构建一个大规模的处理系统
-
从设计上就内建错误容忍机制
-
对大文件的优化,特别是数据追加以及读取
-
不局限于现有的文件系统接口,为了应用进行接口的扩张
-
尽量使用简化的设计,如单个主服务器single master,简化系统的结构,便于理解与维护
GFS以及相关的开源等价软件包括HDFS,MooseFS等限制的部署都非常广泛,验证了这个结构的有效性。