【工业与大数据】流处理 —— 云计算的重要处理模式

一、流计算的必要性
- 流计算的需求
- Map-Reduce,Spark,GraphLab都是批处理模型,会面临如下挑战
- Volume 数据量太大以至于存不下全部数据(譬如筛选近十年所有的互联网的词)
- Velocity 数据的到来太快以至于用批处理方式来不及处理
- 使用批处理框架达到所需要性能的成本太高
- Map-Reduce,Spark,GraphLab都是批处理模型,会面临如下挑战
二、什么情况下使用流计算
F(X+△X) = F(X)op(△X)
计算F(X+△X)时不需要对全部数据集 X+△X进行计算,只需要将X之前的某种处理结果保留下来,并和增量△X处理结果再进行处理。这种处理方式可以看做数据不断增量的方式流入系统并处理,改变系统状态并输出结果。我们把这种方式叫做流计算。
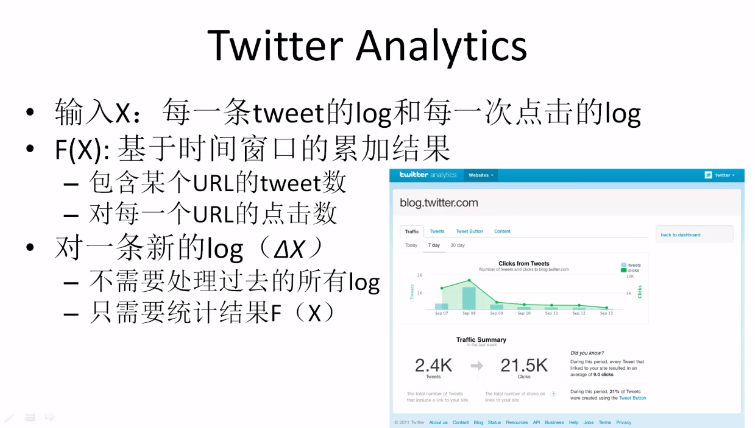
- 举例:Twitter 大规模实时应用
- 平均每秒 6000个tweets,每天约5亿
- 对这些tweets及相关的点击进行统计
三、流计算的技术挑战
- 流计算的目标
- 实时性/可扩展性:
- 批处理任务一般对固定规模数据进行处理,执行时间可以长达几十小时(离线)
- 流处理
- 数据到达速率变化很大(做负载均衡)
- 要么能够处理所有的数据
- 要么预先定义好降级处理的方法
- 容错:系统的错误与系统的故障
- 批处理任务
- 数据错误通常由数据清洗阶段完成
- 系统故障有重算或检查点设置等机制 (MapReduce:从中间结果开始重新计算)
- 流计算
- 数据错误必须实施处理
- 系统故障时的容错机制必须是低开销的,而且还能满足实时性
- 批处理任务
- 可编程性
- 描述自然
- 表达力强
- 无需关注(或少关注)容错机制和负载平衡
- 实时性/可扩展性:
四、流计算的一种简单实现 Worker + Queue (处理+缓冲/路由)
- Worker : 处理单元
- Queue : 缓冲 + 路由 → 解决传入分析系统的数据量不均衡的问题
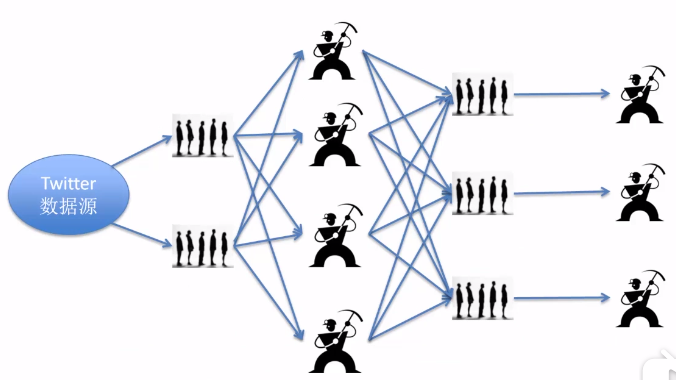
数据传入后,通过负载均衡随机进入(或遵循一定规则)被分配到不同的Queue(队列)
Queue中数据全连接到后续的worker,Worker对数据进行处理,制定接下里要进入的Queue
处理后的Queue与后续的Worker一一对应,解决并发,数据一致性的问题。
Worker Queue存在不易扩展,难容错,编码复杂的问题,所以Twitter替换了这种方式,采用了Strom
五、S4 (Simple Scalable Streaming System)
- 简单的流处理编程接口
- 和MapReduce类似,都是处理key-value
- 有限容错
- 系统节点出错后会重新在备用节点上启动进程
- 当前进程状态丢失,但支持非协调式检查点
- 在运行期间不能增加或删除系统节点
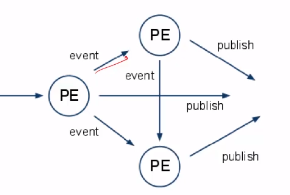
5.1 S4的处理模型 —— Actor模型
- PE(Processiong Element)
- PE之间通过event进行通信
- PE的状态互不可见
- S4框架负责产生PE和消息路由
5.2 S4的设计
- 基于(Key,Attribute)流
- 输入是(K,A)流,S4进行计算,产生中间结果,并(可能)输出一个流
距离:进行wordCount
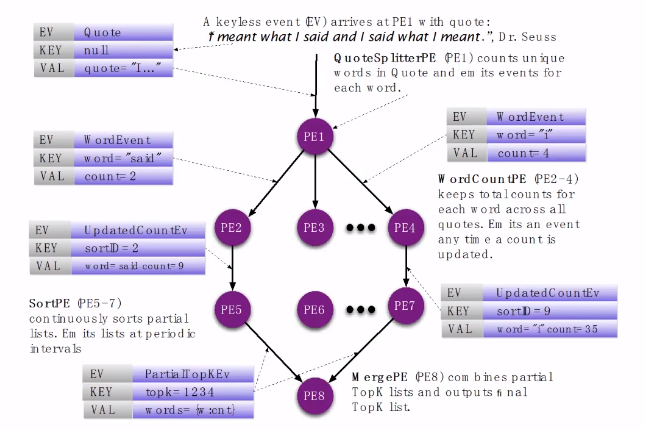
PE
- 功能 :由PE的代码和配置文件定义
- 处理的事件类型
- 每个Key的值对应一个PE
- 在wordcount中,如果遇到一个新词,则会创建一个新的PE
- PE的垃圾收集是一个挑战性问题
- 超时,内存使用情况
Processing Node
- PN是一个逻辑概念
- 每个PE都在一个PN上
- 一个PN包含多个PE
- S4的路由是先到PN,再到PE
- PN到无力节点的映射可以修改,因此可以容错
- 利用Zookepper保存全局信息,协调节点的行为
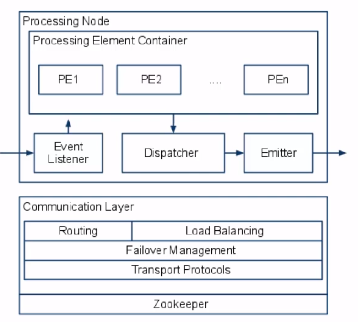
S4的编程模型
private void processEvent(Eventevent ){
queryCount+;
}
public void output(){
String query = (String)this.getKeyValue().get(0);
persister.set(query.queryCount);
}
<bean id="queryCounterPE" class="com.company.s4.processor:QueryCounterPE">
<property name="keys">
<list>
<value>QueryEvent queryString</value>
</list>
</property>
<property name="persister" ref="externalPersister">
<property name="outputFrequencyByTimeBoundary" value="600"/>
</bean>
六、流计算最主流的框架 —— Storm
6.1 Storm的实现
- Tuple(Named list of values):[:name "Chen" :age 40],类似<KEY,VALUE>
- Storm的基本概念
- Stream : Tuple格式的数据流
- Spout :Stream的源头。
- Bolt : 类似于Worker,主要的处理单元。
- Filters 流的分析筛选
- Aggregation 统计,聚合
- Joins 将两个流合并
- 访问数据库
- 运行自定义函数
- Topology : Storm程序被称为Topology
- 数据类型:Storm已经支持所有的primitive type,用户也可以自己定义对象作为value。
- 数据连接(Stream Grouping):Bolts之间相关连接
- Shuffle Grouping 随机
- Field Grouping 根据tuple field的值选取
- All Grouping 发给所有任务
- Global Grouping 发给具有最小id的任务
定义Strom结构的粒子
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words",new TestWordSpout(),10);
builder.setBolt("exclaim1",new ExclamationBolt(),3).shuffleGrouping("words");
builder.setBolt("exclaim2",new ExclamationBolt(),2).shuffleGrouping("exclaim1");
//TestWordSpout()
public void nextTuple(){
Utils.sleep(100);
final String[] words = new String[] {"nathan","mike","jackson","golda","bertels};
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
_collector.emit(new Values(word));
}
// ExclamationBolt()
public void execute(Tuple tuple){
_collector.emit(tuple,new Values(tuple.getString(0)+"!!!!")); //emit的原因是为了后续容错,后面的ack方法使程序知道execute完成了。
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declarer(new Fields("word"));
}
实现WordCount的 Storm代码实例
public static class WordCount implements IBasicBolt{
Map<String,Integer> counts = new HashMap<String,Interger>();
public void prepare(Map conf,TopologyContext context){
//
}
public void excete(Tuple tuple,BasicOutputCollector collector){
String word = tuple.getString(0); //bolt中包含多个词的计数,先找到某个词的count,取出增加计数后,在重新写入bolt。
Integer count = counts.get(word);
cont ++ ;
conts.put(word,count);
collector.emit(new Values(word,count));
}
public void cleanup(){
//
}
public void declareOutputFields(OutputFieldDeclarer declarer){
declarer.declare(new Fields("word","count"));
}
}
运行Storm
```java
LocalCluster cluter = new LocalCluster();
Map conf = new HashMap();
conf.put(Config.TOPOLOGY_DEBUG,true); //Debug模式
cluster.submitTopology("demo",conf,builder.createTopology());
6.2 Storm的容错
- 消息的完整处理
- 每一条消息至少执行一次 at least once
- 通过每条消息 ack() 方法来判断是否完成,如果部分任务没有完成(Timeout)则判断消息没有完整性。为了防止重新计算带来了状态额不一致,采用Transcational(区分计算和提交部分,提交部分按编号传行,计算部分流水线并行)
6.3 S4和Storm的对比
- 编程模型
- S4更简单,编写每个Key的行为就行了
- Storm需要保存和处理更多的东西
- 推还是拉
- S4推,如果缓冲区不够消息就会丢失
- Storm拉,因此丢失的消息来自最初的数据输入
- 容错
- S4不管消息丢失,但是可以恢复状态
- Storm保证消息被处理至少一次
- 社区
- Storm是Apache顶级项目,社区非常活跃,Twitter使用
- S4是Apache incubator项目(孵化器),Yahoo使用