【工业与大数据】内存计算的解决方案 —— Spark

MapReduce作为大数据技术最主流的并行计算方案,仍然存在编程实现较为复杂(麻烦但不难),性能较差的问题。MapReduce在运算过程中会产生大量的IO操作。为了提高性能,我们引入内存计算的概念。
一、背景
1.1 并行计算中的局部性
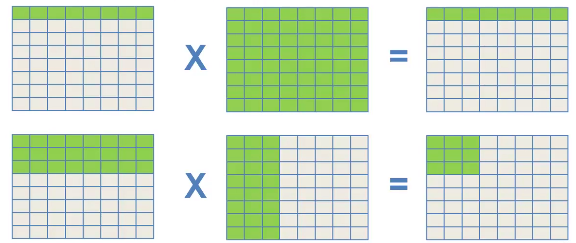
矩阵计算过程中,大量的Catch失效消耗了大量的时间,为了解决这个问题,人们提出了分块运算的思想,我们后面进行详细介绍。
1.2 高可用性
- 大数据处理系统通常是由大量不可靠的的服务器组成的的
- 传统的容错方法不适用
- 锁步法,多版本编程
- 检查点设置与恢复
二、内存计算技术的必要性
大数据处理并行系统,最主要就是对以下三个方面进行权衡
- 编程模型 : 如何识别和描述并行程序
- 性能/成本优化
- 容错能力
虽然MapReduce的发明与实现为开创了大数据的新时代,它很好的解决了自动容错,自动负载均衡,并行化处理的问题,但是随着用户对系统提出了更高的要求时,引入过多I/O操作的MapReduce很难支持复杂的,实时的交互式查询。
所以说MapReduce的瓶颈在于大量的IO操作,这些操作产生的大量数据都需要存储在HDFS中。那么如果我们将MapReduce的中间结果存储在内存中,是否就能大幅度提升MapReduce的效率呢?答案是肯定的,这样的方案比之前速度提升10-100倍!
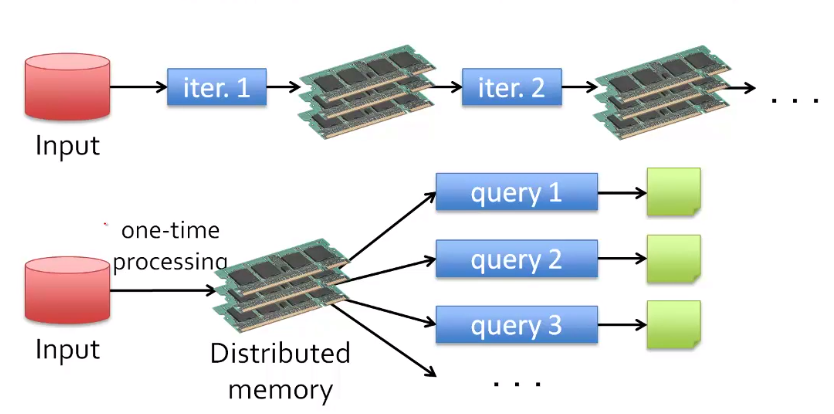
Distributed memory :分布式内存
三、内存计算的可行性
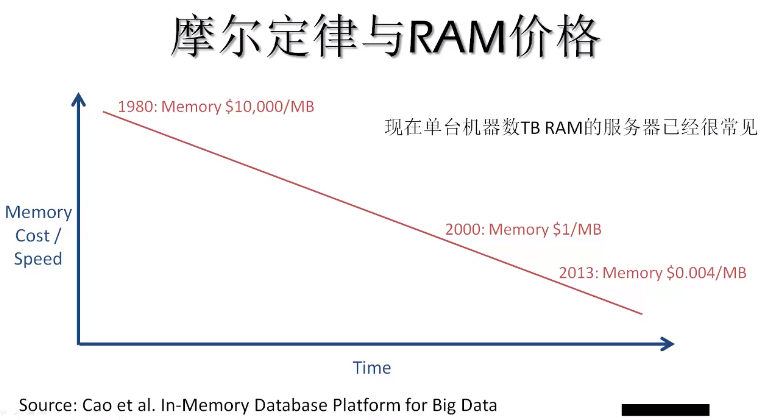
- 内存是否足够大能够装下所需的数据? → 现在单台机器数TB RAM的服务器已经很常见
- 内存有多贵?与硬盘想必性价比如何? → 摩尔定理
- 数据保存在硬盘上,可以保证数据的可用性,放在内存里如果容错?
- 如果高效表示内存里的数据?
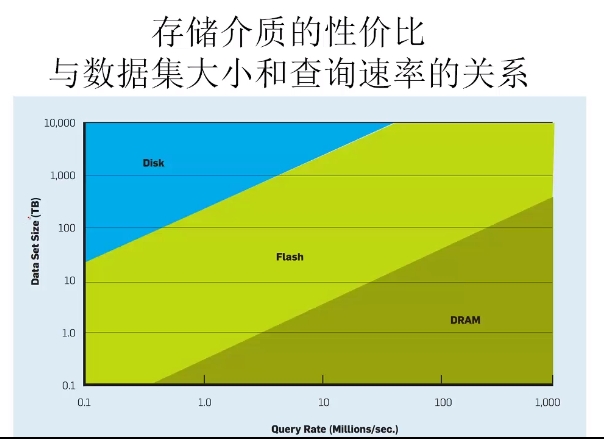
各个内存层次的延迟:DRAM比硬盘块100000倍,但DRAM还是比cache慢6-200
Tape is Dead,Disk is Tape,Flash is Disk,RAM Loacality is king —— Jim Gray
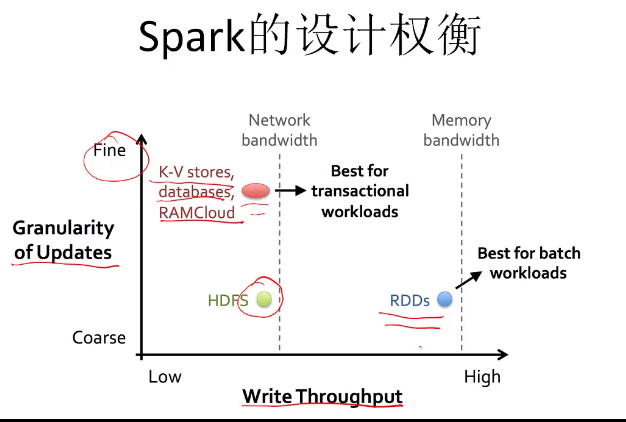
四、 SPARK的设计理念
传统抽象多台机器的内存的方案
- 分布式共享内存(DSM)
- 统一地址空间
- 很难容错
- 分布式键-值存储(Piccolo,RAMCloud)
- 允许细粒度访问
- 可以修改数据(MUTABLE)
- 容错开销大
DSM和键值对的容错机制
-
副本或Log
- 对数据密集应用来说开销很大
- 比内存写要慢10-100倍
4.1 内存处理设计方案
- RDD (Resilient Distributed Datasets)
- 基于数据集合,而不是单个数据
- 由确定性的粗粒度操作产生(map,filter,join等)
- 数据一旦产生,就不能修改(immutable)
- 如果要修改数据,要通过数据集的变换来产生新的数据集
- 高容错性:数据一旦是确定性的产生,并且产生后不会变换
- 就可以通过”重复计算“的方法来恢复数据
- 只要记住rdd的生成过程就可以了,这样一次log可以用于很多数据,在不出错的时候几乎没有开销
message = textFile(...).filter(_.contains("error)).map(_.split('\t')(2))
五、Spark编程技术
- 基于Scala
- 类似Java的一种函数语言
- 可以在Scala控制台上交互式的使用Spark
- 现在也支持Java和Python
- 基于RDD的操作
- Transformation:从现有RDD产生新的RDD
- map,reduce,filter,groupBy,sort,distinct,sample ……
- Action:从RDD返回一个值
- count,collect,first,foreach
- Transformation:从现有RDD产生新的RDD
例子:Log挖掘
将数据空文件系统中调入内存,然后进行交互式的查询
lines = spark.textFile("hdfs://...")
error = lines.filter(_startwith("error"))
messages = errors.map(_.split('\t)(2))
cachedMsgs = messages.cache() //将其存入缓存
cachedMsgs.filter(_.contains("foo)).count
cachedMsgs.filter(_.contains("bar")).count
性能 1TB数据在内存上需要5-7s完成,在硬盘上需要 170s
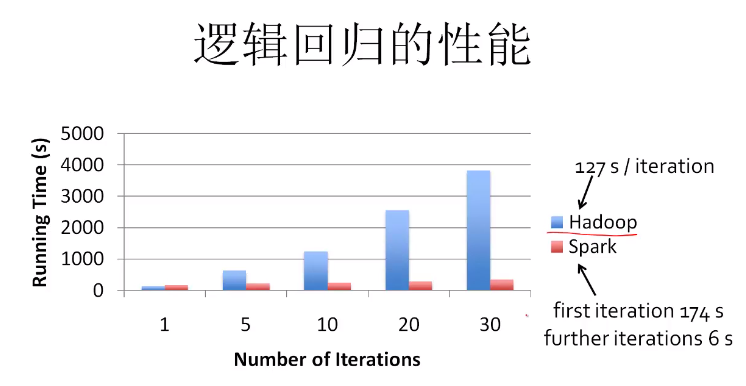
例子:逻辑回归
val data = spark.textFile(...).map(readPoint).cache()
var w = Vector.random(D)
for(i <- 1 to ITERATIONS){
var gradient = data.map(p => (1/(1+exp(-p.y*(w dot p.x))) - 1)*p.y*p.x)
.reduce( _ + _ )
w -= gradient
}
println("final w: ' +w)
例子:WorkCount
var spark = new SparkContext(master,appName,[sparkHome],[jars])
var file = spark.textFile("hdfs://...")
var counts = file.flatMap(line -> line.split(" "))
.map(word => (word,1))
.reduceByKey( _ + _ )
counts.saveAsTextFile("hdfs://,,,")
-
SparkContext 实例化一个spark
-
flatMap 将某一个字段分为多个元素
- line = “a b c a” → (a)(b)(c)(a) → (a,1)(b,1)(c,1)(a,1)
-
reduceByKey → (a,1)(b,1)(c,1)(a,1) → (a,2)(b,1)(c,1)
六、Spark的实现
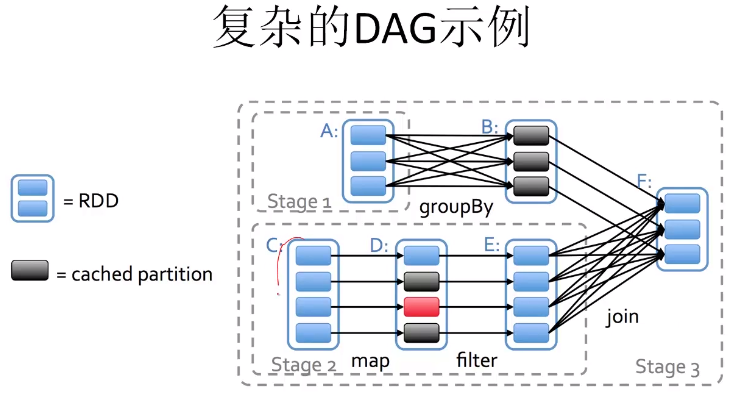
6.1 延迟估值(Lazy Evaluation)
var lines = sc.textFile("data.txt")
val lineLengths = lines.map(s => s.length)
val totalLength = lineLengths.reduce((a,b) => a + b)
前两行都不会出发计算(Transformation)
最后一行的reduce会引发计算,生成DAG
- 复杂的DAG(Directed acyclic grap 有向无环图)
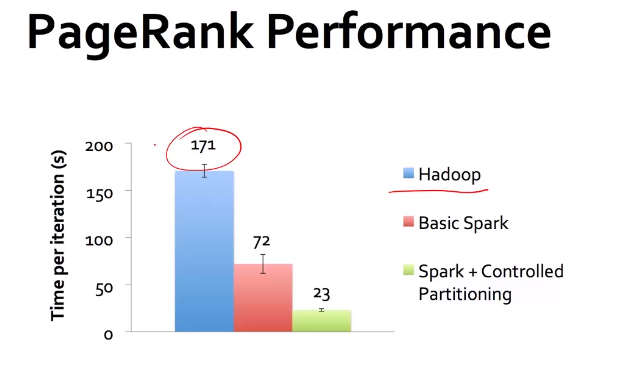
6.2 Spark性能优化
6.2.1 数据划分技术
spark通过数据划分将 links 与
links = // RDD of (url,neighbors) pairs url和相邻的网页
ranks = // RDD of (url,rank) pairs 网页的rank
// 通过不断循环,实现配置rank算法
for(i <- 1 to ITERATIONS){
ranks = links.join(ranks).flatMap{
(url,(links,rank)) => links.map(dest => (dest,rank/links.size))
}.reduceByKey(_ + _)
}

6.2.2 Cache
- 对messages使用cache,意思是将后面可能会重用的数据保存起来,并“尽量”放在内存中
- 正常计算的时候避免重算
- Cache是Persist的特例,是RDD提供的将数据保存在内存的方法
lines = spark.textFile("hdfs://...")
errors = lines.filter(_startsWith("ERROR"))
messages = errors.map(_split('\t')(2))
cachedMsgs = messages.cache()
cachedMsgs.filter(_.contains("bar")).count
StorageLevel列表

- MEMORY_ONLY 2 表示数据保存两份数据
七、Spark的生态环境
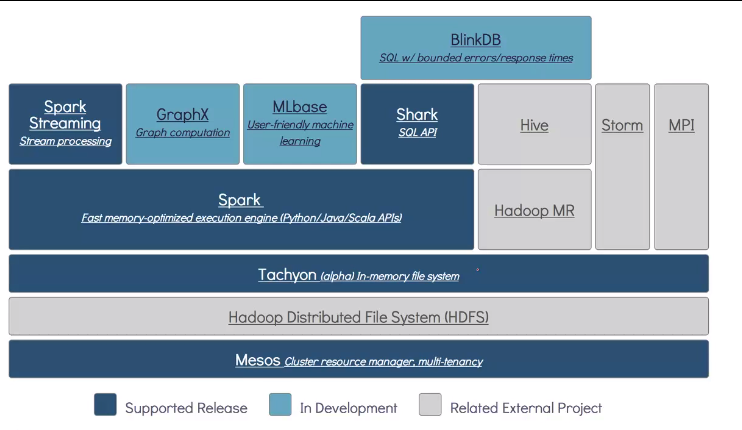
- Spark 是伯克利大学AMP实验室开发的大数据系统
- Mesos : 底层资源管理系统和调度器
- HDFS : Hadoop 文件管理系统
- Tachyon : 内存文件系统
- Spark : 内存计算框架
- Shark : Spark支持SQL API
- Spark Streaming : Spark支持流计算
- GraphX : Spark 支持图算法与模型
- MLbase : Spark 支持机器学习
现在的大数据系统,MapReduce是通用的批处理系统,而其他的工具用于实现专门业务的专用系统,例如Pregel,Giraph,Dremel,Drill,Tez,Impala,GraphLab,Strom,S4。而Spark系统希望将MapReduce一般化(任务DAG和数据共享)并统一编程框架。
然而Spark仍有局限性,Spark进行例如BFS(图遍历)算法过程中每次进行细粒度更新时,无法对RDD内部进行编辑,需要更换新的RDD。从而发生大量无用的内存拷贝,也产生了大量无用数据,导致性能的问题。